Flink基于checkpoint的容错机制是一项标志性功能。因为这一设计,Flink统一了批流处理,能够很容易扩展到极小和极大场景并支持许多类似状态演化实现有状态升级和回滚及时间穿梭的操作功能。
尽管有这些很棒的特性,Flink的checkpoint方式有一个致命弱点:checkpoint速度取决与数据流过整个应用的速度。当应用发生背压时,checkpoint也同样被压(附录1概括了什么是背压,为什么背压可能是好事)。在这种情况下,checkpoint可能会花费更多时间,甚至会超时。
在Flink 1.11版本,社区引入了一个新特性“非对齐checkpoint”来解决这一问题,在Flink 1.12计划进一步拓展其功能。在这两系列博文中,我们会讨论Flink的checkpoint机制是如何被修改来支持非对其checkpoint的,非对齐checkpoint如何工作,以及对用户的影响是什么。在文章1/2中,我们先概述Flink原有的checkpoint过程,核心属性和背压下的问题。
流式应用的状态
简单来说,状态是贯穿多条事件所要记录的信息。即使最小的流式应用也需要状态,因为需要记录输入数据的位置,例如以Kafka分区偏移量和文件偏移量的形式。此外,许多应用需要保持状态来支持其内部操作,例如窗口,聚合,join,状态机。
接下来我们用一个拥有4个有状态算子的流式应用作为例子:

通过checkpoint实现状态持久化
流式应用是长期运行的。他们不可避免会经历软硬件故障,但理想状态下,从外部看应该像故障没有发生过一样。由于长期运行,可能还会积累出很大的状态,在故障后重新计算部分结果可能需要相当长的时间,所以一种持久化和恢复状态的方式是十分必要的。
如下图所示,Flink依赖状态checkpoint和恢复机制来实现这一方式。定期的checkpoint会存储状态快照到存储(通常是对象存或分布式文件系统,诸如:S3,HDFS,GCS这类)。当发生故障时,应用总受影响的部分会被重置到上一次成功checkpoint的状态(通过本地重置或者从存储中加载状态)。
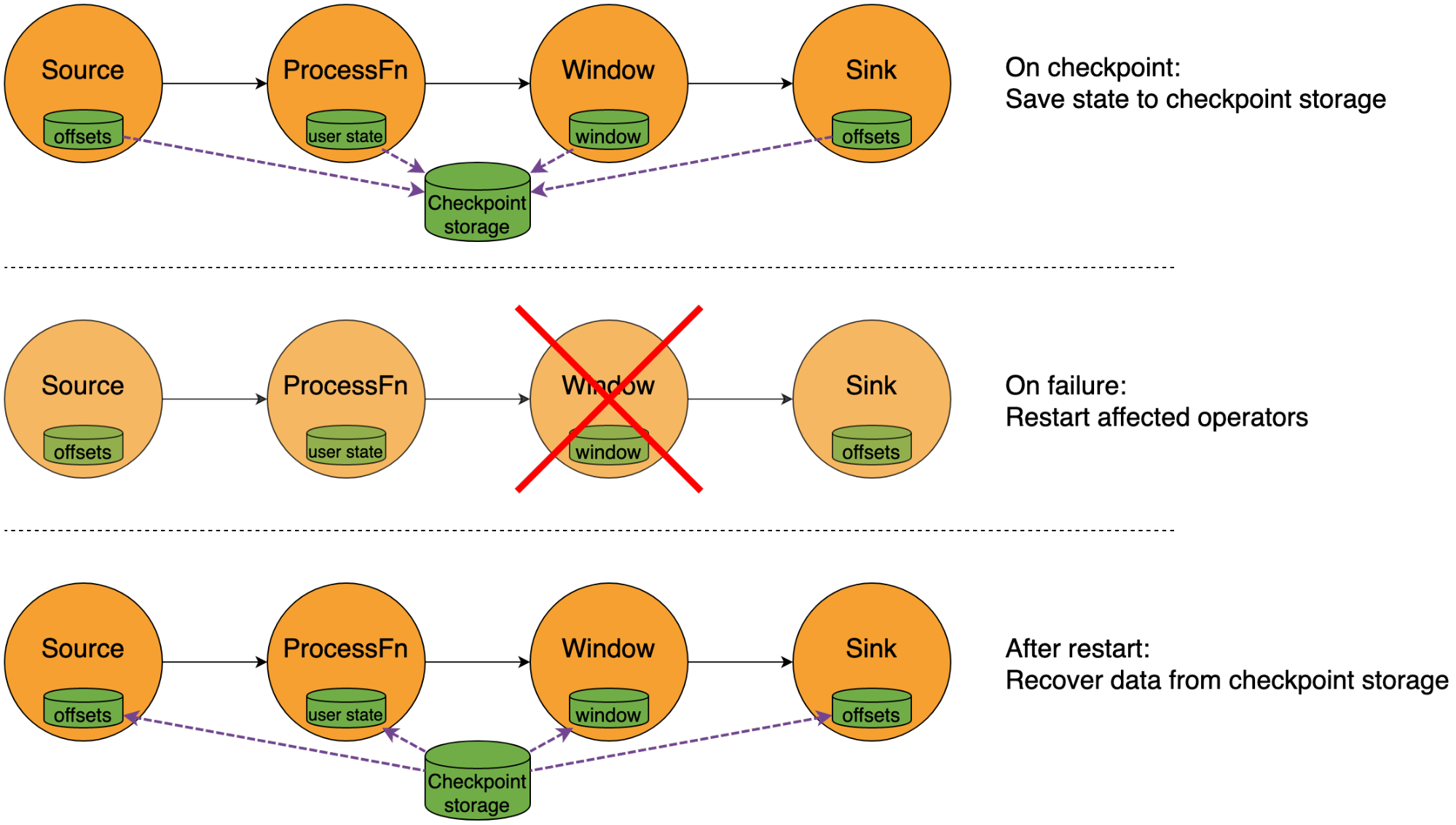
Flink 基于检查点的方式和那些通过将状态保存在分布式数据库或日志的流式系统不同。基于检查点的方式有如下几个更适合Flink的优势:
- Checkpoint外部依赖简单:一个对象存储或者分布式文件系统可能是最具有可用性和易于管理的系统。因为所有的公有云和本地系统都提供该服务,因此Flink非常适合云原生栈。此外,这类存储系统相较于分布式数据库,kv存储,事件broker来讲便宜一个数量级。
- Checkpoint支持版本且不可变: 同时支持版本和不可变输入,checkpoint可以存储不可变快照用于回滚,debugging,测试,或者生产环境之外分析应用状态的一个廉价替代。
- Checkpoint将流传输从持久化机制中解耦:流传输是指数据如何在算子间交换(例如shuffle)。这是Flink流批一体的关键,因为这允许Flink采用低延迟的流式交换或者解偶的批量交换模式。
Checkpoint机制
检查点算法(详情见这篇论文)解决的基本问题是从一个状态一直变化的流式应用中生成一个快照的同时不需要中断事件处理。因为流中总是有事件(网络,I/O buffer等),上下游算子处理事件的时间是不同的:sink算子从11:04开始写入数据,而source从11:06读取数据。理想状态下,所有的快照数据都应该属于相同的时间点,在我们生成快照之前,输入被暂停并等待所有数据流中的数据被抽干(换句话讲pipeline变为空闲)。
为了实现这一特性,Flink在source中插入checkpoint barrier,barrier会流经整个拓扑最终到达sink。这些barrier将流分割成checkpoint前(所有事件持久化到状态或提交到sink)和checkpoint后(不会在state中体现,等待checkpoint完成后被处理)。
下图展示当barrier到达算子时所发生的情况:
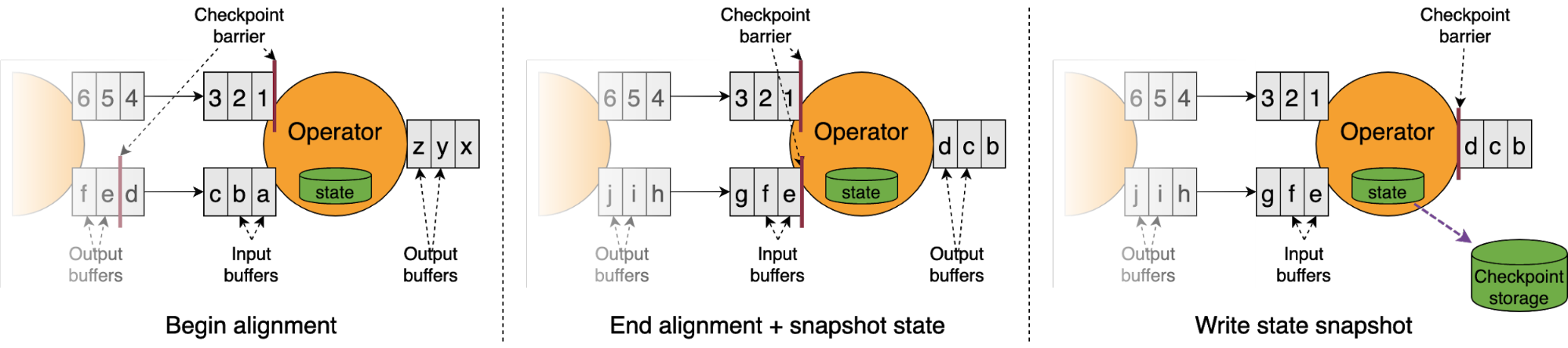
算子需要保证执行checkpoint时所有checkpoint前数据都被处理,所有checkpoint后数据都没有被处理。当首个barrier到达被算子消费的输入缓存队列的头部时,算子开始对齐阶段。在这一阶段算子不会从任何收到barrier的channel消费数据,直到所有channel都收到barrier。
一旦所以barrier都收到,operator就开始生成状态快照,并将barrier发送至下游,然后结束对其阶段,取消对所有输入的阻塞。算子的状态快照被异步写入存储,数据的处理仍在继续。一旦所有算子成功写入快照,这次checkpoint就成功完成,并可用于恢复。
一件重要的事情需要注意,barrier与事件一同严格按顺序在数据流中流动。在一个没有背压的任务中,barrier的流动和对齐时间在毫秒级。checkpoint时间主要受快照写入存储的时间影响,增量检查点的情况下会更快。如果因为背压数据流动变慢,barrier也同样会受到影响。这就意味着barrier要花费更长时间从source流到sink,也就导致对齐阶段需要更长时间。
恢复
当算子从checkpoint重启(自动恢复或者手动从savepoint部署),算子在处理数据前先从存储恢复状态。
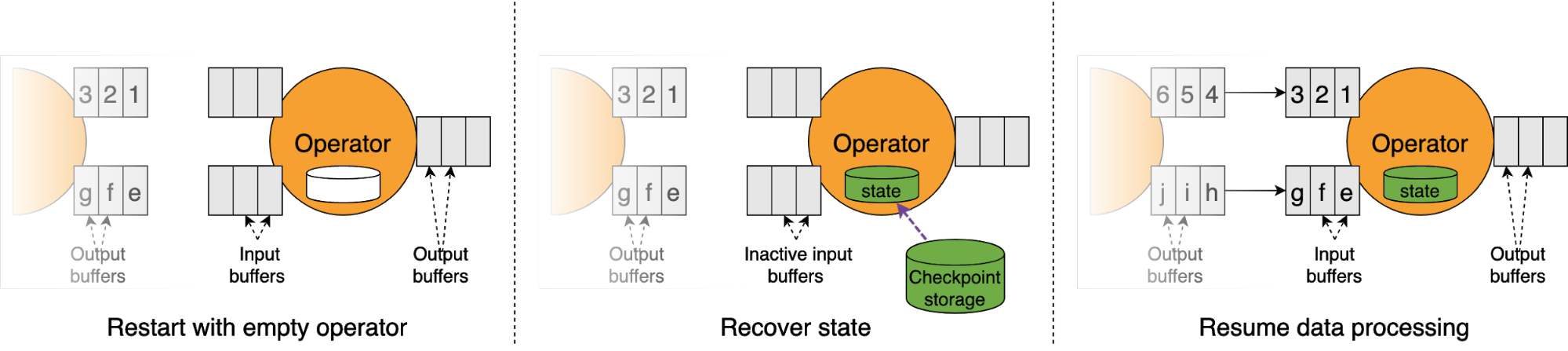
因为source绑定到检查点中的offset,恢复时间通常计算为恢复处理数据的时间与处理数据至失败点位置所花费额外时间之和。当一个应用出现背压,恢复时间还包括恢复起始直至被压被消除的时间。
一致性保证
对齐阶段只有在Flink默认的exactly-once语义下才需要。如果一个应用在at-least-once语义下执行,checkpoint对齐期间不会阻塞任何channel,这会在算子恢复时带来数据重复开销。
这不应该和只在sink中使用at-lease-once语义混淆,许多用户选择at-lease-once sink而不是 transaction sink因为许多sink 算子是幂等或者收敛至相同结果(例如kv存储的输入输出)。在中间算子中使用at-least-once语义通常不是米等的(例如简单的count聚合)因此推荐大多数用户使用exactly-once checkpoint。
结论
这篇文章概括了Flink的容错机制(基于对齐checkpoint)如何工作,以及为什么checkpoint适合容错流式计算。checkpoint机制被逐步优化,使得生成检查点更快更廉价(异步增量检查点)更快恢复(本地缓存),但是基本概念(barrier,对齐,状态快照)还是保持原有版本。
下一部分会深入对原有机制checkpoint机制的改造来避免对齐阶段,最近引入的“非对齐checkpoint”。请期待第二部分对于非对其checkpoint工作原理以及背压时保证一致性的介绍。
附录1 背压
背压是指慢接受者使得发送者变慢来避免被压跨而丢失数据或请求。这对于看重完整性和正确性的系统来讲是至关重要和理想的。背压在很多分布式系统中隐式实现,例如TCP流控,有界IO队列,轮询消费者等。
Flink在整个数据流中实现背压。一个暂时无法跟上数据发生的sink会导致source更慢的拉取数据。我们相信这是一个理想的行为,因为背压不仅仅能避免接受者被压跨,还可以防止流式应用不同stage差距太远。
考虑如下例子:我们有一个source(Kafka读取数据),解析数据,通过key group聚合,然后写入到sink(数据库)。这个应用需要在解析和重新分组之间对数据按照key重新分组。
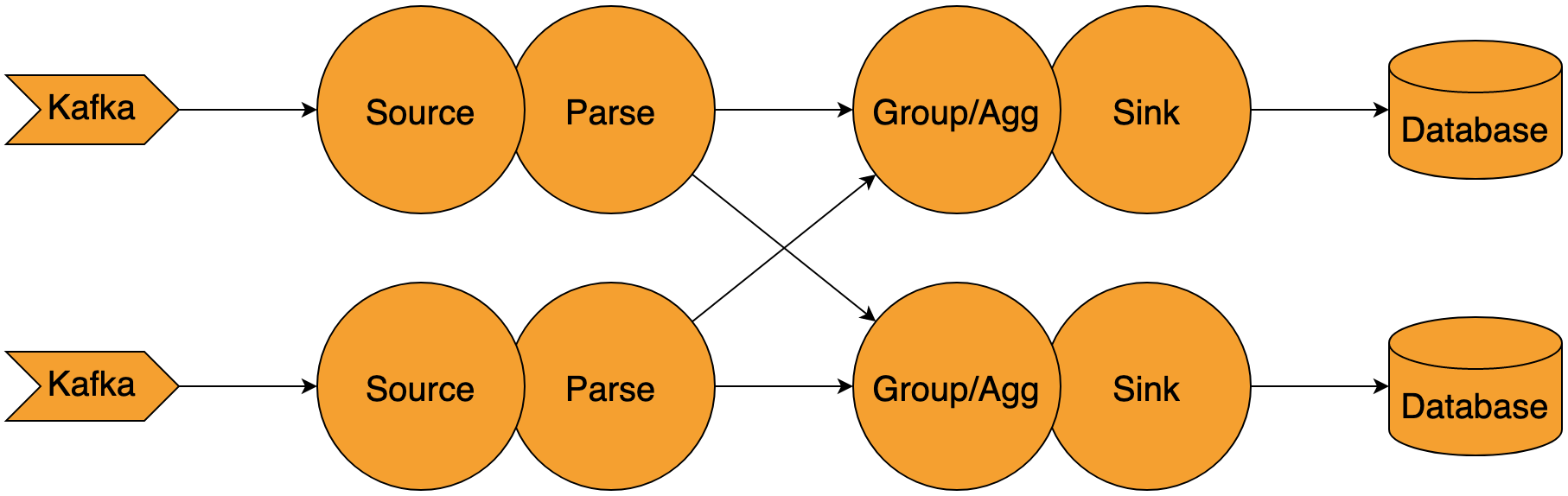
假设我们使用非背压的方式,例如写入数据到日志或者MQ来进行重新分组(Kafka Stream就是使用此方式)。如果sink现在比其他部分更慢(很容易出现),第一个stage(source和parse)仍然会全力读取数据并解析后写入shuffule日志。这个中间日志会积累大量数据,意味着需要大量的容量才能在最坏情况下保存输入数据的副本,否则的话就会导致数据丢失(当超出保存时间)。
使用背压时,source/parse阶段会减速来匹配sink,保证整个应用对于数据处理步调更加一致,避免需要大量中间结果的存储。