动机
此FLIP旨在解决当前流式source接口(SourceFunction)的一些问题和短板,同时统一流批的source接口。我们要解决的缺点或要点:
-
当前批流的source实现是不同的。
-
“工作发现”(splits,partition等)和实际的数据“读取”混杂在SourceFunction接口和DataStream API中,导致注入Kafka和Kinesis这类source的实现十分复杂。
-
Partitions/shards/splits在接口中不明确。这使得实现一个source无关的特定方法十分困难,例如event-time对齐,per-partition watermarks,动态split分配,工作窃取。例如,Kafka和Kenesis消费者支持per-partition watermarks,但是从Flink 1.8.1开始只有Kinesis消费者支持event-time对齐(选择性从splits中读取数据,确保在事件时间中均匀推进)。
-
Checkpoint锁归source function所有。实现类必须保证在加锁状态发射元素和进行状态更新。Flink无法优化实现对锁的处理。
这个锁是非公平的。在锁竞争情况下,某些线程可能无法获取到锁(checkpoint线程)。
这也阻碍了算子的lock-free actor/mailbox线程模型。 -
没有公共块,意味着所有source的实现都必须自行实现复杂的线程模型。这使得实现和测试一个新source很困难,而且也为已存在source做贡献增高了门槛。
全局设计
设计有几个关键方面会在各章节进行讨论。这些讨论能够帮助更好的理解public interface的设计。
将工作发现和读取分离
Source有两大组件:
- SplitEnumerator: 发现和分配splits(文件,分区等等)
- Reader:从splits中读取数据
SplitEnumerator类似于老批处理source接口中splits创建和分配功能。它只执行一次,不会并行(但如果有必要可以在未来考虑并行化)。
它可能运行在JobManager或者在一个TaskManager的task中(见下面“从哪里执行Enumerator”)。
例如:- 在File Source中, SplitEnumerator 列举所有文件(可能会细分为块/范围)。
- 在Kafka Source中,SplitEnumerator发现所有需要读取的Kafka分区。
Reader从被分配的splits中读取数据。Reader涵盖了现有source接口大部分功能。有些readers可能按顺序逐一读取有界splits,有些则可能并行读取多个(无界)splits。
Enumerator和reader的分离允许不同枚举策略和reader的组合。例如,当前的Kafka connector有不同的分区发现策略与其他代码耦合在一起。有了新的接口,我们只需要一个split reader实现,并且可以有多个split enumerators用于不同的分区发现策略。
有了这两个组件封装核心功能,主要的Source接口只是一个用于创建split enumerators和readers的工厂接口。

流批一体
每一个source都应该能作为有界(批)和无界(流)source工作。
有界性是source本身的固有属性。在大多数情况下,只有
SplitEnumerators知道有界性,二SplitReaders是不可知的。
这样可以在显示建模有界流时,还可以在未来使得API变的类型安全。
DataStreamAPI
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
FileSource<MyType> theSource = new ParquetFileSource("fs:///path/to/dir", AvroParquet.forSpecific(MyType.class));
// The returned stream will be a DataStream if theSource is unbounded.
// After we add BoundedDataStream which extends DataStream, the returned stream will be a BoundedDataStream.
// This allows users to write programs working in both batch and stream execution mode.
DataStream<MyType> stream = env.source(theSource);
// Once we add bounded streams to the DataStream API, we will also add the following API.
// The parameter has to be bounded otherwise an exception will be thrown.
BoundedDataStream<MyType> batch = env.boundedSource(theSource);例子
FileSource
- 对于有界输入,使用SplitEnumerator遍历路径下所有文件
- 对于持续输入,使用SplitEnumerator周期性检测并分配路径下新文件
KafkaSource
- 对于有界输入,使用SplitEnumerator列举所有分区并获取最新offset作为每个split的结束offset。
- 对于持续输入,使用SplitEnumerator列举所有分区,并使用LONG_MAX作为split结束offset。
- Source可能还有一个选项用于持续发现新分区。仅适用与“持续输入”。
通用enumerator-reader通信机制
SplitEnumerator和SourceReader都是用户实现类。需要二者之间通信的实现并不少见。为了方便这样的用例。在这个FLIP,我们引入一个SplitEnumerator和SourceReader间的通用消息传输机制。这一机制需要JobMasterGateway和TaskExecutorGateway间额外的RPC方法对。消息传输栈如下所示:
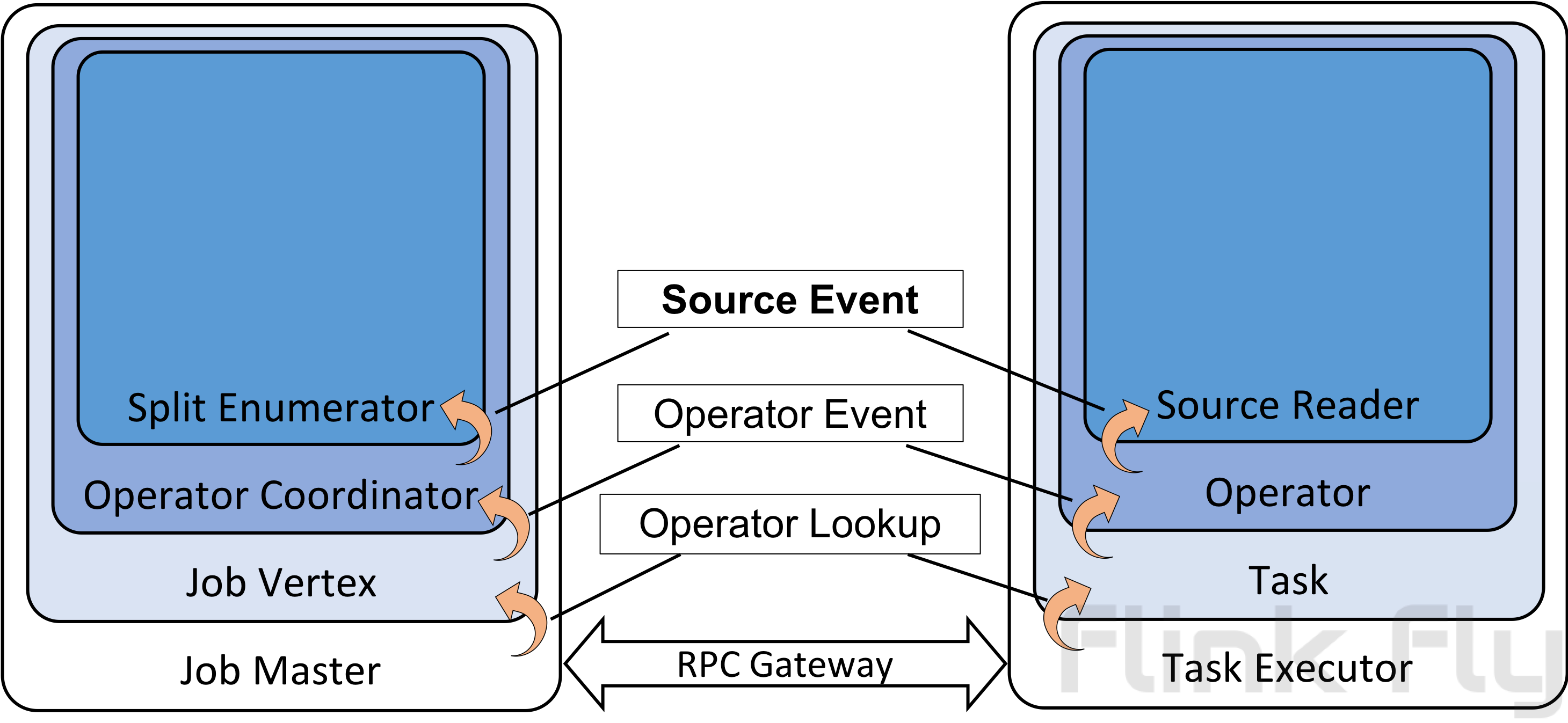
SourceEvent是消息的接口。OperatorEvent 是算子协调者与算子间消息的接口。OperatorCoordinator是通用的,可以与任务算子关联。在这一FLIP中,SourceCoordinator是OperatorCoordinator的实现,封装了SplitEnumerator。
Reader接口和线程模型
Reader需要满足以下属性:
- 没有封闭的工作循环,这样就不需要处理锁。
- 非阻塞方法,支持其运行在 actor/mailbox/dispatcher 风格的算子。
- 所有的方法都被同一个线程调用,实现者不需要处理并发问题。
- Watermark/Event time处理被抽象成可扩展来进行split感知和对齐(见下方“Split独立Event-time”和“Event-time对齐”)。
- 所有的readers都自然地支持状态和checkpoints。
- Watermark生成在批处理中应该被规避。
以下核心方面为我们提供了这些属性: - Split同时是source中工作分配和状态的类型。分配或者从checkpoint恢复一个split对于reader来讲是相同的。
- 推进reader是一个返回future的非阻塞操作。
- 我们在主接口的基础上构建更高级别的原语(见下方:“高级Readers”)。
- 我们在SourceOutput中隐藏了event-time/watermarks,并且会针对批(没有watermark)和流(有watermark)传递不同的source context。SourceOutput同样抽象了每个分区watermark的追踪。
SourceReader会作为一个PushingAsyncDataInput执行,它与新的mailbox线程模型在tasks中工作良好,类似于网络输入。
基础实现和高级readers
核心的source接口(最底层接口)是非常通用的。这使得其十分灵活,但是对于贡献着来讲难以实现,特别是对于 Kafka 或 Kinesis 这类足够复杂的reader模式。
通常来说,connectors使用的大多数IO库都是非异步的,我们需要启动一个I/O线程来使得其对主线程不阻塞。
我们提议通过建立高级source抽象提供允许阻塞调用的更简单接口来解决这一问题。
这些高级抽象同样可以解决source同时处理多个splits和独立event-time的问题。
大多数readers都可以归类到以下类别:
- 一个reader,1个split(某些简单块readers)
- 一个reader,多个splits。
a. 顺序单个split(文件,数据库查询,大多数有界splits)
b. 多split多路复用(Kafka,Pulsar,Pravega, ...)
c. 多split多现场(Kinesis, ...)
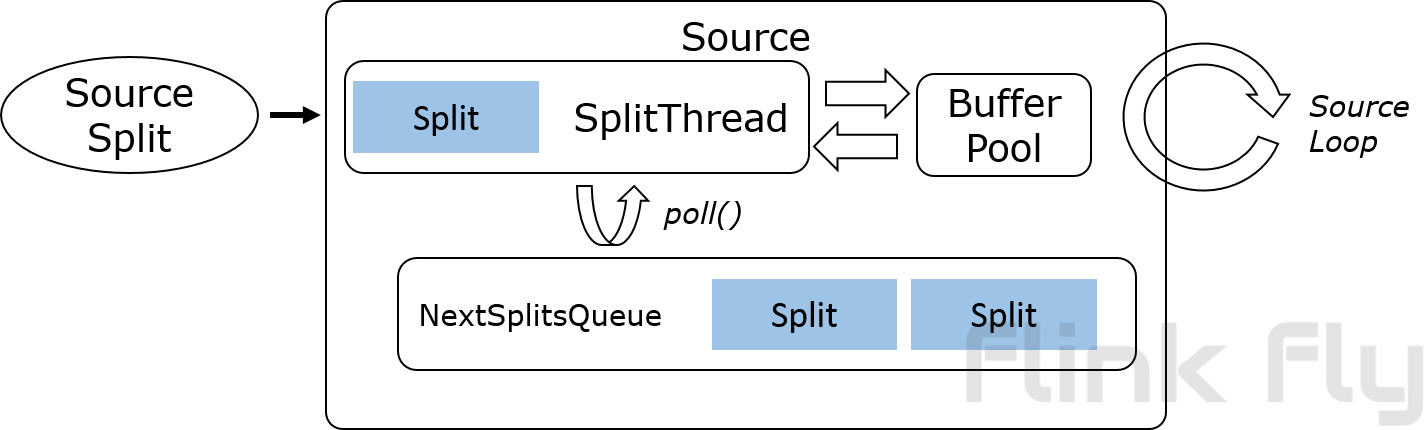
大多数针对高级构建实现的readers只需要实现与此类似的接口。另外还规定,除了wakeup()方法外,所有方法都被同一线程调用,避免在connector中需要任何并发处理。
SourceReader reading methods
public interface SplitReader<E, SplitT extends SourceSplit> {
RecordsWithSplitIds<E> fetch() throws InterruptedException;
void handleSplitsChanges(Queue<SplitsChange<SplitT>> splitsChanges);
void wakeUp();
}SplitReader 返回的RecordsWithSplitIds会被逐一传递给RecordEmitter。RecordEmitter负责以下事务:
- 将原始记录类型
转换为最终记录类型 - 提供被处理记录的event time时间戳。
有了以上基础实现,用户在实现自己的source时可以专注于:- 从外部系统取记录。
- 进行记录解析和转换。
- 抽取时间戳并处理watermark(可选)。接下来的一个FLIP会提供默认行为供用户处理watermark。
基础实现可以大致说明如下:

一些简短的解释:
- 当一个新的split被SplitEnumerator添加到SourceReader时,split在被分配给SplitReader前,初始状态被放进一个由SourceReaderBase维护的state map中。
- 记录以RecordsBySplitIds的形式从SplitReaders传递到RecordEmitter。这允许SplitReader可以按批的形式将记录加入队列,有利于提升性能。
- SourceReaderBase遍历每一条记录并查找其对应split的状态。记录和其对应split状态被一同传递给SplitReader。
注意这个基础实现的抽象没有指定反序列化在哪里执行。因为RecordEmitter是由task中主mailbox线程驱动的,理想状态下反序列化应该由split reader完成,这样更具有扩展性。也有可能通过引入一个线程池来做这件事。然而,反序列化的具体实现不是这个FLIP关注的重点,会有后续的FLIP来涵盖。
基础实现使用的接口在这一章节:
故障转移
SplitEnumerator的状态包含以下信息:
- 未分配的splits
- 已分配但尚未成功checkpoint的splits
- 已分配但尚未成功checkpoint的splits所属的checkpoint id。
SourceReader的状态包含以下信息:
- 已分配splits
- Splits的状态(例如:Kafka offsets, HDFS文件offset等)
当SplitEnumerator失败时,将执行完整的故障转移。可能有更细粒度的故障转移,只需要恢复SplitEnumerator的状态,我们会在单独的FLIP来解决这一问题。
当SourceReader失败时会尝试恢复到最近一次成功checkpoint。SplitEnumerator会通过回收已分配但未checkpoint的split实现部分状态重置。在这种情况下,只有失败的子任务和与之关联的节点需要重置状态。
Enumerator在哪里运行
关于在enumerator在哪里运行有一个很长的讨论记录在附录中。我们最终采取的方式非常类似于选项3,但又有一点不同。方法如下。
每一个SplitEnumerator被封装在一个SourceCoordinator中。如果有多个sources,就会有多个SourceCoordinator。SourceCoordinators会运行在JobMaster,但是不作为执行图的一部分。在这个FLIP,我们提议一旦SplitEnumerator失败就故障转移整个执行图。一个更细粒度的enumerator故障转移会在后续的FLIP中提出。
Split独立Event Time
通过引入SourceSplit,我们可以为每一个split提交event time。我们计划在单独的FLIP提出解决方案以降低复杂度。
Event Time对齐
Event Time对齐在SplitEnumerator和SourceReader间的通用沟通机制引入后更容易实现。在这一FLIP不会包含以降低复杂度。
公开接口
这个FLIP引入的公开接口的变更包含3个部分。
- 顶层公共接口。
- 作为顶层公共接口基础实现所引入的接口。
- 提供了大多数Source实现所需公共方法的基础实现。
- 通用消息传递RPC网关接口的变更。
值得注意的是我们虽然会权力维护稳定的接口,但作为基础实现的一部分所引入的接口(例如SplitReader)比顶层接口(例如SplitEnumerator/SourceReader)更可能发生变化。这主要是因为随着时间推移,我们想添加更多功能到基础实现中。
顶层公开接口
- Source - 工厂式的类用来在执行环境创建SplitEnumerator和SourceReader。
- SourceSplit - 所有split类型的接口。
- SplitEnumerator - 发现splits并分配给SourceReaders。
- SplitEnumeratorContext - 提供SourceReader和SplitEnumerator通信所必须的方法。
- SourceOutput - collector式的接口用来获取SourceReader所提交的时间戳和记录。
- WatermarkOutput - 一个用来提交watermark和指示source空闲的接口。
- watermark - 一个新的Watermark类被创建在org.apache.flink.api.common.eventtime包下。这个类会最终替换现有的org.apache.flink.streaming.api.watermark包下的Watermark类。这一改变允许flink-core与其他模块间保持独立。考虑到我们最终会将所有watermark的生成放到Source中,这一修改是有必要的。注意这一FLIP不打断修改watermark在DataStream中发出可被修改这一现有方式。
以下代码省略
基础实现的公开接口
以下是基础实现引入的高级接口。
- SourceReaderBase - SourceReader的基础实现。使用下列接口。
- SplitReader - 无状态无线程的高级reader,只负责从被分配splits中读取原始记录。
- SplitChange - 对split reader的split改变。目前只有一个SplitAddition子类。
- RecordsWithSplitIds - 一个用于存储原始记录的容器。允许SplitReader拉取并传递记录给SourceOutput。
以下代码省略
RPC网关公开接口
TaskExecutorGateway
public interface TaskExecutorGateway extends RpcGateway {
...
/**
* Sends an operator event to an operator in a task executed by this task executor.
*
* <p>The reception is acknowledged (future is completed) when the event has been dispatched to the
* {@link org.apache.flink.runtime.jobgraph.tasks.AbstractInvokable#dispatchOperatorEvent(OperatorID, SerializedValue)}
* method. It is not guaranteed that the event is processes successfully within the implementation.
* These cases are up to the task and event sender to handle (for example with an explicit response
* message upon success, or by triggering failure/recovery upon exception).
*/
CompletableFuture<Acknowledge> sendOperatorEvent(
ExecutionAttemptID task,
OperatorID operator,
SerializedValue<OperatorEvent> evt);
...
}JobMasterGateway
public interface JobMasterGateway {
...
CompletableFuture<Acknowledge> sendOperatorEventToCoordinator(
ExecutionAttemptID task,
OperatorID operatorID,
SerializedValue<OperatorEvent> event);
...
}附录 - Enumerator在哪里运行
Enumerator和SourceReader之间的通信有一下要求:
- 懒加载/拉取式分配:只有当reader请求下一个split时enumerator才发送一个split,这样可以获得更好的负载均衡。
- “拉取”消息载荷,用于“位置”这类信息从SourceReader到SplitEnumerator的通信,从而能够支持位置感知这类功能。
- 利用checkpointing实现Exactly-once容错:一个split只被发送到reader一次。一个split要么是enumerator的一部分(以及其checkpoint),要么是reader的一部分,或者是已经完成。
- checkpoint之间Exactly-once(也包括没有checkpointing):在检查点之间(包括checkpoints缺失的情况下),已经分配给readers的splits在故障恢复时必须重新添加到enumerator。
- 通信信道不得将任务连接到单个故障转移区域。
鉴于这些要求,有3种选项来实现这个通信:
选项1:Enumerator运行在TaskManager
SplitEnumerator作为一个并行度为1的task执行。Enumerator任务的下游是并行执行的SourceReader任务。通信通过数据流进行。
Reader通过发送“反向事件”来请求splits,类似于批迭代种的“请求分区”或者“超步同步”。这些不会暴露在算子中,但tasks可以访问它们。
Task对反向事件做出反应:只有收到事件时才会发送一个split。这给了我们给予懒加载/拉取式的分配。反向事件消息(例如为了位置感知)载荷是可能的。
因为splits通过数据channel,checkpoints和splits天然对齐。Enumerator是source的唯一入口任务,也是唯一接受“触发检查点”RPC请求的。
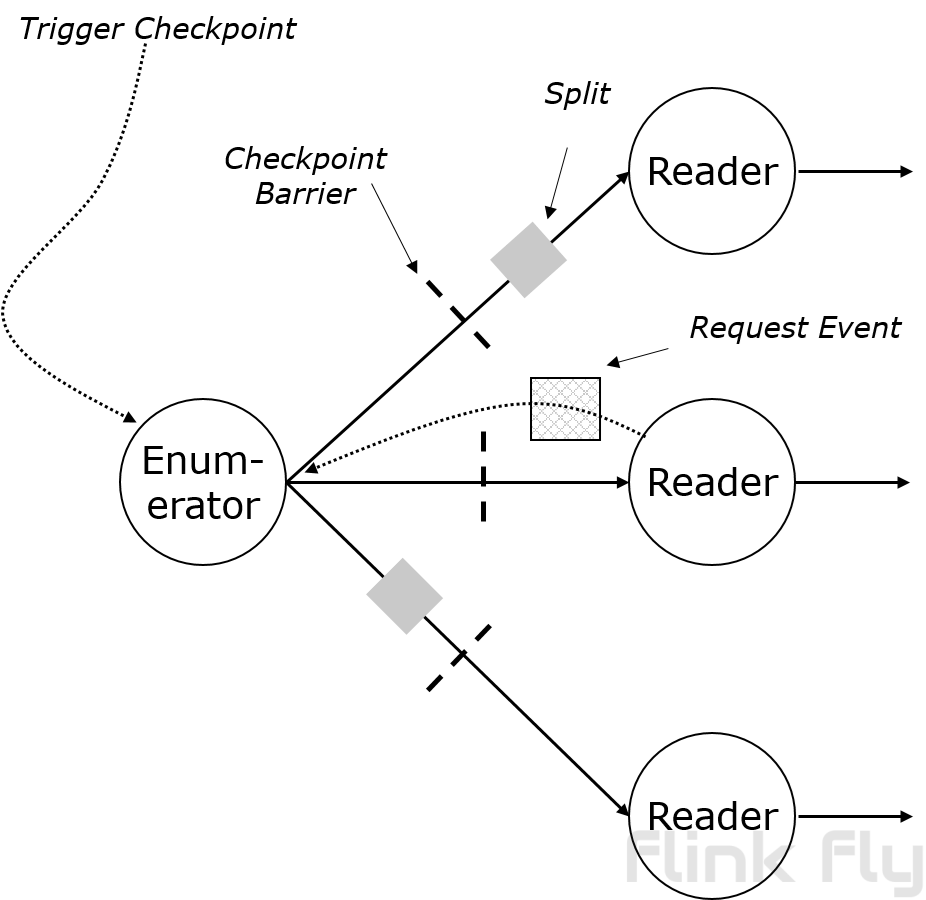
Enumerator和split reader之间的网络连接被调度器视为故障转移的边界。
为了解耦enumerator和reader重启,我们需要以下一种机制:
- 流水线持久化通道:两次checkpoint之间通道中的内容是持久化的。一个接收任务在“checkpoint x 之后”请求数据。数据在checkpoint x+1完成后被清理。
当一个reader失败,恢复的reader任务可以在检查点之后重连到该stream并获得之前被分配的splits。
批处理是一个特例,如果没有checkpoints,channel会从开始保存所有数据。- 优点:“流水线持久化通道”还有超出enumerator和reader之间的连接的应用。
- 缺点:Splits总是被分发到同一个reader而且不能在恢复时分散到多个readers。特别是对于批处理应用,这可能会造成恢复时出现落后者。
- 失败重连和任务通知:Enumerator任务需要记住分配给每个结果分区的split直至下一次checkpoint完成。在下游任务出现失败时enumerator任务也需要被通知并添加splits回enumerator。恢复的reader任务只需要简单重连来获取一个新的stream。
- 优点:在故障恢复时所有splits重新分散(没有落后者)。
- 缺点:打破了分离任务和网络栈的抽象。
选项2:Enumerator运行在JobManager
类似于当前批处理(DataSet)输入split分配者,SplitEnumerator运行在JobManager,作为ExecutionJobVertex的一部分。为了支持定期split发现,enumerator需要定期被额外线程调用。
Readers通过RPC请求splits,enumerator通过RPC应答。RPC消息携带诸如位置一类的载荷。
额外需要关注的是split分配和checkpoint barriers的对齐。如果我们开始支持基于元数据的水印(用来支持处理有界splits集合event time的一致性),我们需要支持通过RPC与输入split分配进行对齐。
Enumerator在checkpoint被触发时创建自己的checkpoint状态。
这里的关键点在于对master(ExecutionGraph)和checkpoint增加了复杂度。在目前单线程执行图dispatcher情况下,通过rpc将它们对齐是可能的,但如果要支持异步checkpoint写入则需要更多的复杂性。
选项3:引入一个新的SourceCoordinator独立组件,Enumerator运行在SourceCoordinator上
SourceCoordinator 是一个独立的组件,不作为执行图的一部分。SourceCoordinator作为一个独立进程运行在JobMaster。设计上没有限制。与SourceCoordinator(Enumerator)之间的通信是通过RPC。Split分配是通过RPC支持拉取式。SourceReader需要注册到SourceCoordinator(地址在TaskDeploymentDescriptor或者由JobMaster通过RPC更新)然后发送携带载荷的split请求。
每一个Job之多有一个由JobMaster启动的SourceCoordinator。因为可能有多个不同的sources,一个Job可能有多个Enumerators,所有的Enumerators执行在这一个SourceCoordinator。
Split分配需要满足checkpointing模式语义。Enumerator有自己的状态(split分配),它们是全局checkpoint的一部分。当一次新的checkpoint被触发,CheckpointCoordinator先发送barriers到SourceCoordinator。
SourceCoordinator对所有Enumerators的状态生成快照。然后SourceCoordinator通过RPC发送barriers到SourceReader。Split和barrier在RPC是FIFO的,所以Flink自然可以对齐split分配与checkpoint。
如果用户指定RestartPipelinedRegionStrategy作为故障转移策略,情况就略微有些复杂。这个模型中没有故障转移区域的问题,因为Enumertaor和SourceReader之间没有执行边的存在(SourceCoordinator不是执行图的一部分),我们需要分开解释。
- 当一个SourceReader任务失败,JobMaster不会重启SourceCoordinator或Enumerator。JobMaster取消其他与故障任务在相同故障转移区域的任务。JobMaster通知Enumerator 失败或取消的SourceReader任务(可能有多个SourceReader在同意失败区域)以及要恢复的checkpoint版本。通知在重启新任务前发出。当Enumerator感知到task失败,恢复失败任务相关的状态到指定的checkpoint版本。这意味着SourceCoordinator需要支持部分恢复。Enumerator还在内存保存一个SourceReader的两级map,包含checkpoint版本和split分配情况。这个map有助于找到需要重新分配或添加回enumerator的splits。应该有不同的策略用于处理这些失败的splits。在某些基于事件时间的job里,重新分配失败的splits到其他task会破坏watermark语义。恢复split分配状态之后,重建内存中的map并处理失败的splits,Enumerator返回一个通知给JobMaster,然后JobMaster重启失败区域的tasks。这里可能有一个优化是Enumerator立刻返回通知给JobMaster而不需要等待恢复。因此失败区域的任务重新调度和Enumerator的恢复可以同时处理。另一个重要的事情是在Enumerator恢复过程中,其他SourceReaders应该正常工作,包括获取下一个split。
- 当Enumerator或者SourceCoordinator失败,如果有一个预写日志存在(下面会提到),JobMaster应该重启Enumerator或者SourceEnumerator,但不重启SourceReader tasks。在重启后,Enumerator恢复状态,重放预写日志,然后开始工作。与此同时,SourceReader等待连接,暂时不会有splits被分配直至注册成功。注册是有必要的。需要在预写日志重放完成后有一个Enumerator和SourceReader之间的对齐,因为Enumerator不能保证最后一次split分配到各个SourceReader是成功还是失败。如有有必要,重新连接的信息由JobMaster更新(进程崩溃)。如果没有预写日志,故障转移会退化成全局的故障转移,所有的tasks和Enumerators都会重启并从上一次成功checkpoint恢复。
CheckpointCoordinator应该通知Enumerator checkpoint以及完成。这样Enumerator可以清空在内存和预写日志的map数据。