先来看一个简单的Spark任务:
ss.sparkContext.sequenceFile(inputPath, classOf[Text], classOf[BytesWritable])
.map(i => (i._1.toString.split("#")(1), (i._1.toString, i._2.copyBytes())))
.repartitionAndSortWithinPartitions(new HashPartitioner(partition))
.map(_._2)
.saveAsSequenceFile(outputPath, Option.apply(classOf[ZStandardCodec]))任务关键配置为:
spark.executor.memory=2g
spark.executor.cores=1
spark.executor.memoryOverhead=1g
spark.serializer=org.apache.spark.serializer.KryoSerializer这个任务在执行时多个Executor出现了堆内存溢出,任务读取的文件单条数据最大为几百KB,任务中也没有任何大量消耗内存的操作,2G内存理论上是完全足够的,为什么还是会内存溢出呢?
这时候大家会想到通过dump堆内存来分析,如果Yarn集群没有提供dump的能力,可以通过添加参数来实现dump堆内存并上传到hdfs,方便后续分析:
--conf spark.executor.extraJavaOptions="-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath="./dump.hprof" -XX:OnOutOfMemoryError='/usr/bin/hdfs dfs -put ./dump.hprof hdfs://bj04-region01/user/oleg/oom_dump/dump_$(date +%Y%m%d%H%M%S)_%p.hprof;kill -9 %p'"通过分析dump文件发现,堆内存绝大部分都被org.apache.spark.util.collection.ExternalSorter对象所使用,看来它就是罪魁祸首了!
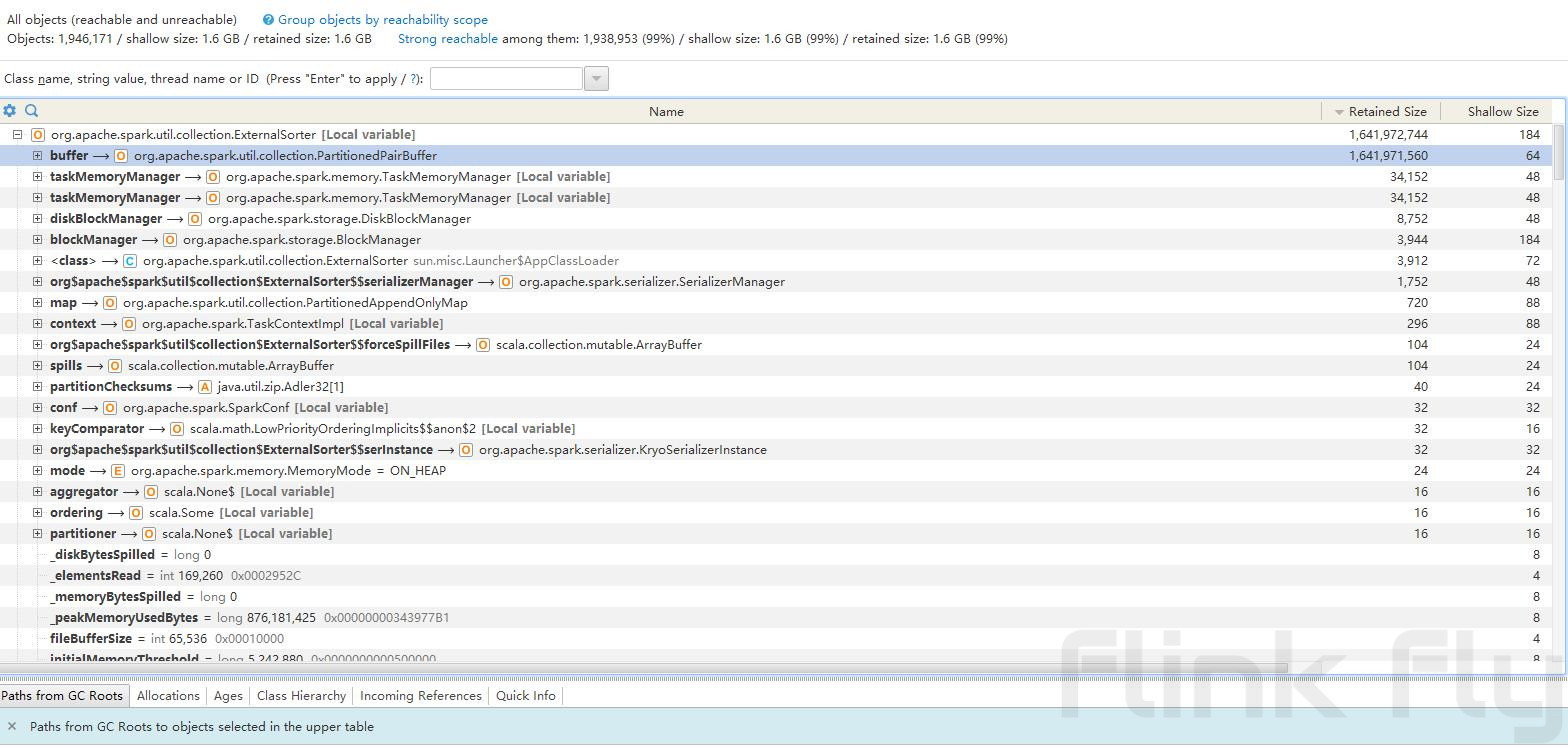
Spark执行shuffle时ExternalSorter将数据缓存到内存中进行排序,在内存不足时触发spill将数据写入磁盘来释放内存,为什么这里没有正常进行spill呢?来分析一下触发spill的逻辑:
protected def maybeSpill(collection: C, currentMemory: Long): Boolean = {
var shouldSpill = false
if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) { //已使用内存超过限额才能触发spill
// Claim up to double our current memory from the shuffle memory pool
val amountToRequest = 2 * currentMemory - myMemoryThreshold
val granted = acquireMemory(amountToRequest)
myMemoryThreshold += granted
// If we were granted too little memory to grow further (either tryToAcquire returned 0,
// or we already had more memory than myMemoryThreshold), spill the current collection
shouldSpill = currentMemory >= myMemoryThreshold
}
shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold
// Actually spill
if (shouldSpill) {
_spillCount += 1
logSpillage(currentMemory)
spill(collection)
_elementsRead = 0
_memoryBytesSpilled += currentMemory
releaseMemory()
}
shouldSpill
}spill的在当前已使用内存大于等于可使用内存时才会触发,而这个已使用内存是通过采样(为了效率)预估出来的,通过分析dump文件中的数据我们发现,Spark预估的数据和实际值相差巨大:
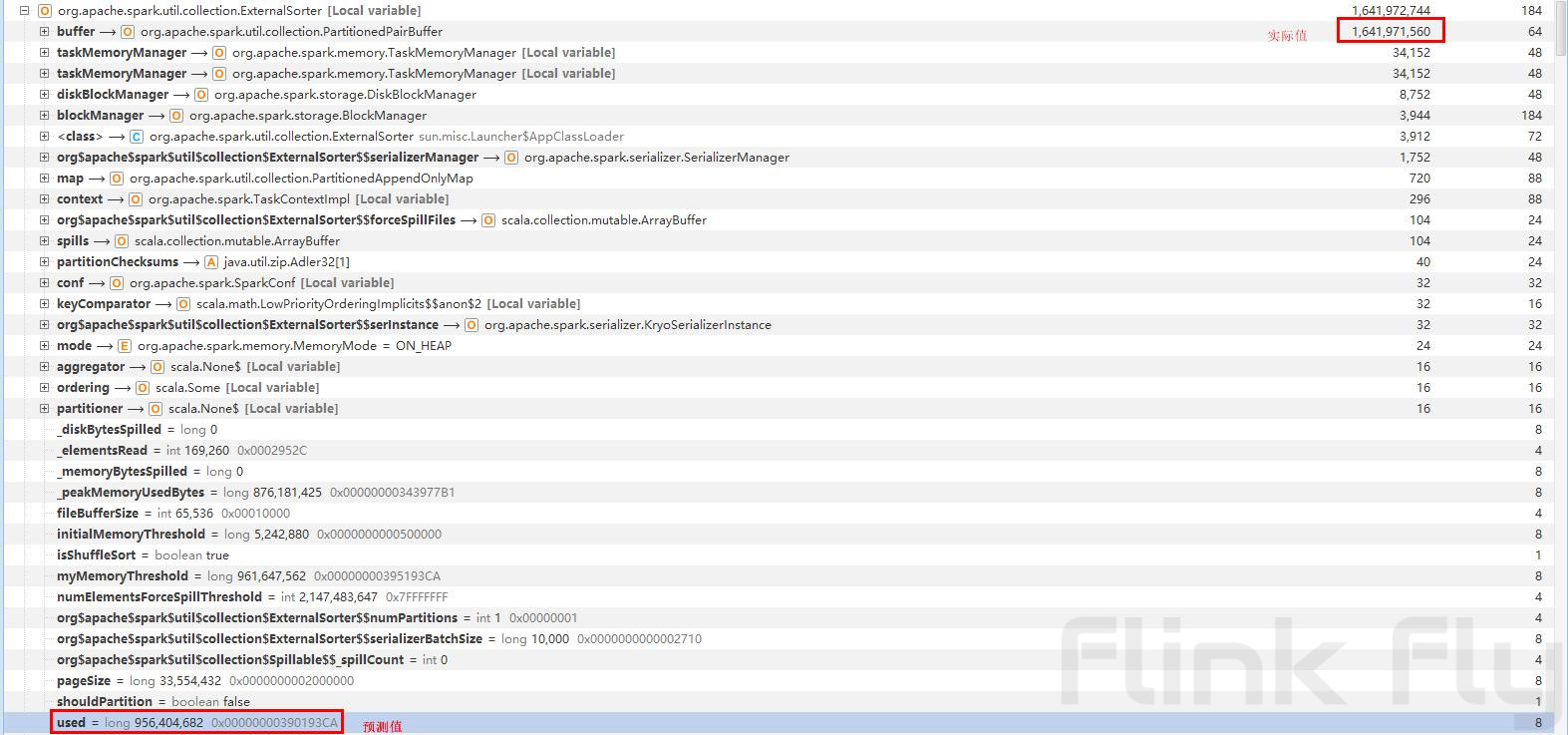
由于单条数据大小存在巨大差异,让Spark错误的估算了当前已使用的内存,不断的写入新数据而没有及时spill到磁盘才导致了最终的内存溢出。当堆内存越大时,缓存的数据越多,估算的偏差越大,更容易出现溢出。
知道了原因那该怎么修复这个问题呢?
- 加内存:最简单粗暴的方法,只要内存大小超过整个分区的数据大小,就算估算有偏差也不会溢出。会产生较大的资源浪费,当数据量超过集群单个容器的内存限额也无法使用这种方式,所以不推荐使用。
- 增加分区数量:通过增加分区数量使得每个分区的数据量变少,可以在不加内存的情况下避免溢出,但是当分区数过多时会导致数据碎片化,大量的随机读会严重影响shuffle service性能。
- 限制缓存的数据量:通过限制缓存数据量来减少估算内存的误差来及时触发spill,这里有两种方式:
- 降低堆大小
spark.executor.memory=1g:适合计算逻辑没有大量占用内存的情况 - 适当调小execution memory的大小
spark.memory.fraction=0.6/(1641971560/956404682)=0.35:在计算逻辑需要占用大量内存时(例如:加载内存字典),可以通过降低execution memory的占比来预留更多内存,避免溢出
- 降低堆大小
方式3通过更频繁的触发spill来避免内存的溢出,那会不会因为磁盘IO导致任务执行变慢呢?实际任务测试的效果如下图:
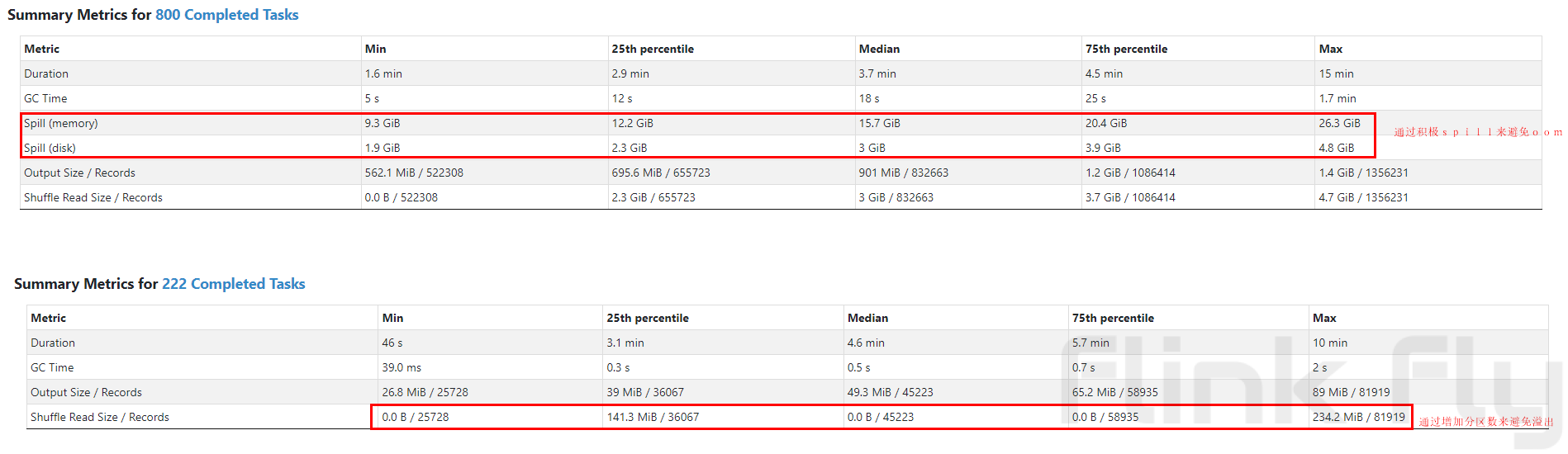
从上图可以看出:方式3触发了spill,但是在单个分区处理的数据量大20倍左右时,整体执行时间反而好于没有发生spill的方式2的小分区策略,从任务执行时间统计来进行分析:
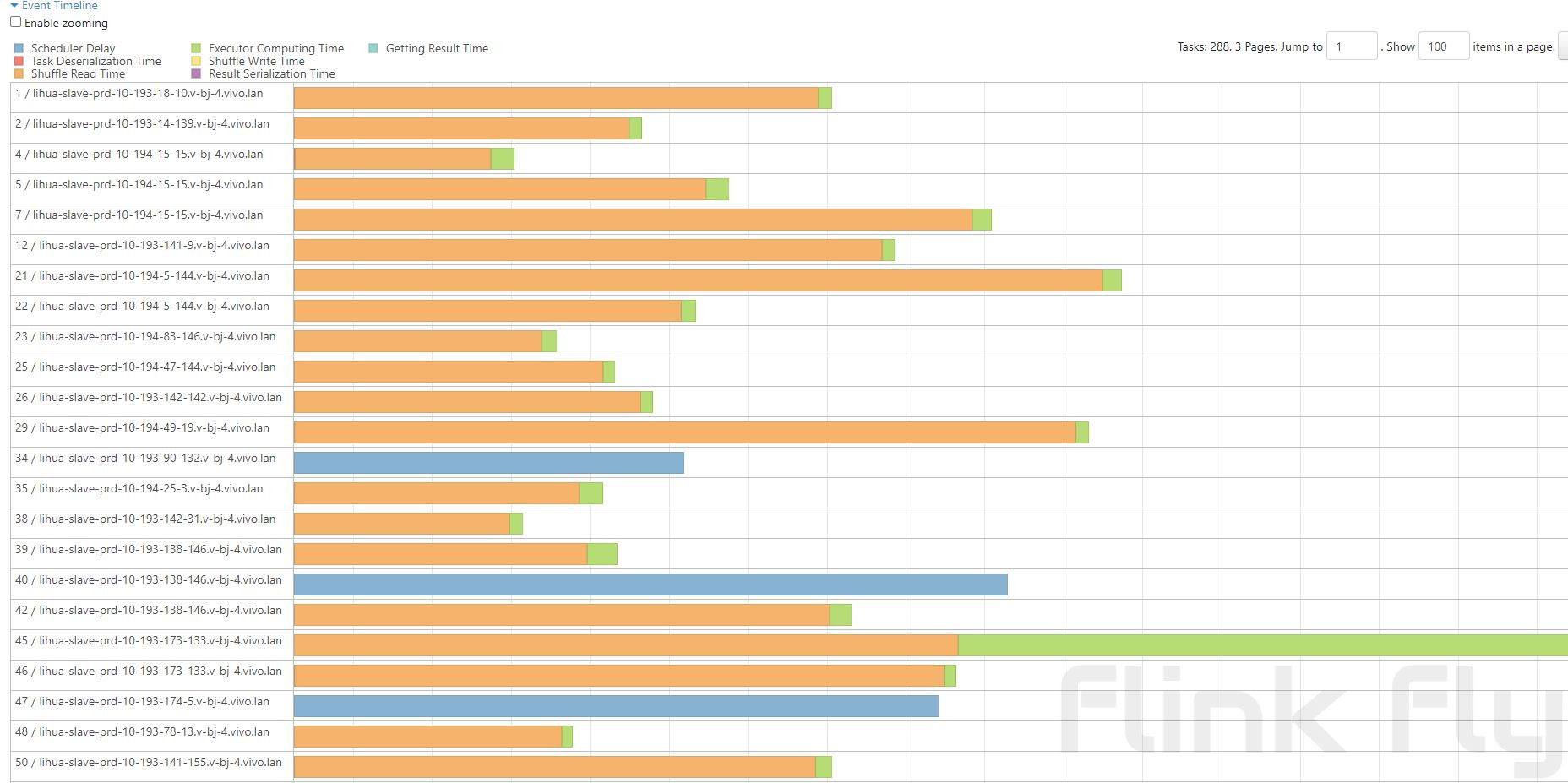
可以看到大量的时间都在进行shuffle read,其原因就是大量分区造成的随机读影响了任务性能。所以在没有对shuffle service进行优化的大数据量场景下通过及时触发spill来避免溢出是更加合理的选择。