上一篇文章我们通过一个真实案例介绍了Spark任务堆内存溢出的排查思路和方法,接下来啃一个硬骨头:Container killed by YARN for exceeding physical memory limits。
如果你经常在Yarn集群执行Spark任务,一定会遇到这个异常,我们只知道Executor使用的内存超过了向Yarn申请的内存,但是具体原因如何排查呢?为什么-Xmx参数已经限制了堆内存大小,还是会溢出呢?
1.JVM内存构成
要解决这个问题,我们先要了解JVM的内存构成:
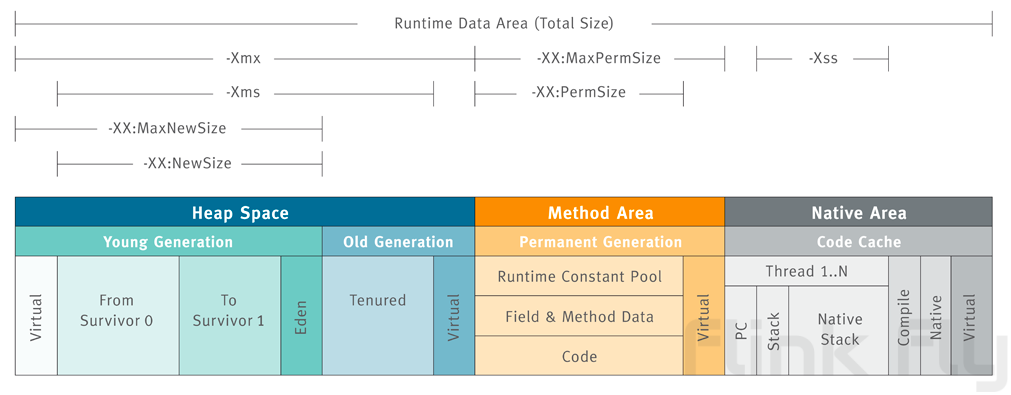
Heap Space:也就是堆内存,大小由Xmx和Xms控制,由jvm负责进行垃圾回收,溢出时会产生java.lang.OutOfMemoryError: Java heap space错误
Method Area:存放运行时常量池、类型信息等。
- 在Java8以前的版本通过永久代的方式实现,一旦溢出会报
java.lang.OutOfMemoryError: PermGen space错误。 - 从Java8开始通过Metaspace来实现,一旦溢出会报
java.lang.OutOfMemoryError: Metaspace错误。
方法区也由jvm进行垃圾回收,在没有进行大量动态类生成时通常也不会产生溢出,即使溢出后也有明确的异常,所以也不是目前关注的重点。
Native Area:包含栈,本地方法栈,编译信息,本地内存。栈和本地方法栈由于自身特性不需要进行回收,最有可能占用大量内存的就是本地内存。
2.本地内存溢出的表现
以执行在Yarn集群的Spark任务为例,一个Container占用的内存为:
executor-memory + spark.executor.memoryOverhead + spark.executor.pyspark.memory(默认0) + spark.memory.offHeap.size(默认0)
--executor-memory通过设置Xmx限制了堆内存的大小,是个无法超越的硬限制,但是对于非堆的占用却是通过内存检测实现的,即:定时检测进程树占用的总物理内存,当占用超过上述公式计算结果时就将Container杀掉,在Spark中看到的就是万恶的报错信息:Container Killed by Yarn For Exceeding Memory Limits,此时就能够确认是本地内存溢出了。
3.如何排查本地内存溢出问题
本地内存溢出的常见原因有:
- JNI调用的共享库申请了内存,没有及时释放
- 在Java代码里调用了Unsafe.allocateMemory或者ByteBuffer.allocateDirect申请了大量本地内存
- 启动的子进程占用了大量内存
那么该如何确认是哪个原因导致的呢?
4.系统调用追踪神器strace
任何应用的内存分配都必须通过系统调用实现,我们可以通过在executor启动一个strace来进行内存相关系统调用的跟踪:
public static void strace() {
String pid = ManagementFactory.getRuntimeMXBean().getName().split("@")[0];
Process process = null;
System.out.println("【开始strace监控】");
try {
process = Runtime.getRuntime().exec("strace -e trace=%memory -k -f -p " + pid);
print(process.getErrorStream());
print(process.getInputStream());
process.waitFor();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (process != null)
process.destroy();
}
}
private static void print(InputStream stream) {
new Thread(() -> {
try {
int c;
while ((c = stream.read()) != -1) {
System.out.print((char)c);
}
} catch (Exception e) {
e.printStackTrace();
}
}).start();
}例如通过Unsafe分配1G内存的调用可以得到如下结果:
1721809] mmap(NULL, 1073745920, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0ebffff000
> /usr/lib/x86_64-linux-gnu/libc-2.31.so(mmap64+0x26) [0x118b06]
> /usr/lib/x86_64-linux-gnu/libc-2.31.so(pthread_attr_setschedparam+0x2bc9) [0x97979]
> /usr/lib/x86_64-linux-gnu/libc-2.31.so(pthread_attr_setschedparam+0x39e3) [0x98793]
> /usr/lib/x86_64-linux-gnu/libc-2.31.so(__libc_malloc+0x1b9) [0x9a299]
> /home/a/workspace/jdk1.8.0_192/jre/lib/amd64/server/libjvm.so(os::malloc(unsigned long, MemoryType)+0xf5) [0x902505]
> /home/a/workspace/jdk1.8.0_192/jre/lib/amd64/server/libjvm.so(Unsafe_AllocateMemory+0xfa) [0xa9402a]
> unexpected_backtracing_error [0x7f0f69018407]我们可以通过libjvm.so(Unsafe_AllocateMemory+0xfa)确认是调用的Unsafe_AllocateMemory本地方法来分配的内存,只要在代码中找到相关调用进行确认即可。
比较可惜的是Java使用了JIT编译,strace没有办法精确定位到Java代码栈,对于JNI调用的共享库则没有这个问题。
5.NodeManager日志
对于子进程导致的内存超限问题,NodeManager的日志也是辅助排查的关键信息。Container被杀时Yarn会打印出进程树的详细内容,方便我们定位出问题的进程:
2024-03-28 12:38:31,518 INFO org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Memory usage of ProcessTree 109154 for container-id container_e10_1711596357803_18015_01_000023: 1.4 GB of 2 GB physical memory used; 3.2 GB of 4.2 GB virtual memory used
2024-03-28 12:38:35,767 INFO org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Memory usage of ProcessTree 109154 for container-id container_e10_1711596357803_18015_01_000023: 2.8 GB of 2 GB physical memory used; 6.2 GB of 4.2 GB virtual memory used
2024-03-28 12:38:39,973 INFO org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Memory usage of ProcessTree 109154 for container-id container_e10_1711596357803_18015_01_000023: 2.8 GB of 2 GB physical memory used; 6.2 GB of 4.2 GB virtual memory used
2024-03-28 12:38:39,973 WARN org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Process tree for container: container_e10_1711596357803_18015_01_000023 has processes older than 1 iteration running over the configured limit. Limit=2147483648, current usage = 2988670976
-------------------------
2024-03-28 12:39:37,720 WARN org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl: Container [pid=109154,containerID=container_e10_1711596357803_18015_01_000023] is running beyond physical memory limits. Current usage: 2.8 GB of 2 GB physical memory used; 6.2 GB of 4.2 GB virtual memory used. Killing container.
Dump of the process-tree for container_e10_1711596357803_18015_01_000023 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 176240 109158 109154 109154 (java) 0 0 3284054016 364455 /usr/java/jdk1.8.0_192-amd64/bin/java -server -Xmx1024m -XX:MaxDirectMemorySize=256m -Djava.io.tmpdir=/data7/yarn/nm/usercache/a/appcache/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023/tmp -Dspark.history.ui.port=18081 -Dspark.driver.port=33657 -Dspark.port.maxRetries=500 -Dspark.network.timeout=300s -Dspark.shuffle.service.port=7338 -Dspark.ui.port=0 -Dspark.yarn.app.container.log.dir=/data4/yarn/container-logs/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023 -XX:OnOutOfMemoryError=kill -9 %p org.apache.spark.executor.YarnCoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@cluster1-submit-prd-10-197-17-4.v-bj-5.vivo.lan:33657 --executor-id 22 --hostname cluster1-slave-prd-10-193-137-36.v-bj-4.vivo.lan --cores 1 --app-id application_1711596357803_18015 --resourceProfileId 0 --user-class-path file:/data7/yarn/nm/usercache/a/appcache/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023/__app__.jar --user-class-path file:/data7/yarn/nm/usercache/a/appcache/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023/hadoop-lzo-0.4.15-cdh5.14.4.jar
|- 109158 109154 109154 109154 (java) 61199 4761 3284054016 364455 /usr/java/jdk1.8.0_192-amd64/bin/java -server -Xmx1024m -XX:MaxDirectMemorySize=256m -Djava.io.tmpdir=/data7/yarn/nm/usercache/a/appcache/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023/tmp -Dspark.history.ui.port=18081 -Dspark.driver.port=33657 -Dspark.port.maxRetries=500 -Dspark.network.timeout=300s -Dspark.shuffle.service.port=7338 -Dspark.ui.port=0 -Dspark.yarn.app.container.log.dir=/data4/yarn/container-logs/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023 -XX:OnOutOfMemoryError=kill -9 %p org.apache.spark.executor.YarnCoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@cluster1-submit-prd-10-197-17-4.v-bj-5.vivo.lan:33657 --executor-id 22 --hostname cluster1-slave-prd-10-193-137-36.v-bj-4.vivo.lan --cores 1 --app-id application_1711596357803_18015 --resourceProfileId 0 --user-class-path file:/data7/yarn/nm/usercache/a/appcache/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023/__app__.jar --user-class-path file:/data7/yarn/nm/usercache/a/appcache/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023/hadoop-lzo-0.4.15-cdh5.14.4.jar
|- 109154 109152 109154 109154 (bash) 1 0 116043776 746 /bin/bash -c LD_LIBRARY_PATH="/usr/hdp/3.1.4.0-315/hadoop/lib/native/:/opt/cloudera/parcels/CDH/lib/hadoop/lib/native:/opt/cloudera/parcels/GPLEXTRAS/lib/hadoop/lib/native:/opt/cloudera/parcels/GPLEXTRAS-5.14.4-1.cdh5.14.4.p0.3/lib/impala/lib:/opt/cloudera/parcels/GPLEXTRAS-5.14.4-1.cdh5.14.4.p0.3/lib/hadoop/lib/native:/opt/cloudera/parcels/CDH-5.14.4-1.cdh5.14.4.p0.3/lib/hadoop/lib/native" /usr/java/jdk1.8.0_192-amd64/bin/java -server -Xmx1024m '-XX:MaxDirectMemorySize=256m' -Djava.io.tmpdir=/data7/yarn/nm/usercache/a/appcache/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023/tmp '-Dspark.history.ui.port=18081' '-Dspark.driver.port=33657' '-Dspark.port.maxRetries=500' '-Dspark.network.timeout=300s' '-Dspark.shuffle.service.port=7338' '-Dspark.ui.port=0' -Dspark.yarn.app.container.log.dir=/data4/yarn/container-logs/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023 -XX:OnOutOfMemoryError='kill -9 %p' org.apache.spark.executor.YarnCoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@cluster1-submit-prd-10-197-17-4.v-bj-5.vivo.lan:33657 --executor-id 22 --hostname cluster1-slave-prd-10-193-137-36.v-bj-4.vivo.lan --cores 1 --app-id application_1711596357803_18015 --resourceProfileId 0 --user-class-path file:/data7/yarn/nm/usercache/a/appcache/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023/__app__.jar --user-class-path file:/data7/yarn/nm/usercache/a/appcache/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023/hadoop-lzo-0.4.15-cdh5.14.4.jar 1>/data4/yarn/container-logs/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023/stdout 2>/data4/yarn/container-logs/application_1711596357803_18015/container_e10_1711596357803_18015_01_000023/stderr 通过进程树可以发现,Java进程109158出现了一个克隆进程176240,这会让进程树的物理内存占用翻倍,NodeManager检测到内存超限后杀掉了Container。
为什么会产生一个一模一样的克隆进程呢?这是因为JVM通过vfork + exec的方式来创建一个新的进程:
- vfork系统调用复制一个子进程,子进程完全复用父进程的内存空间,复制完成后父进程挂起
- 子进程继续执行,子进程调用exec来加载要执行的可执行文件,重新分配内存空间
- 父进程继续执行
从上述流程就能看出,vfork后到exec之前进程树中就会出现一个NodeManager日志中的克隆进程,而NodeManager是每3秒钟检测一次进程树,如果一个进程连续出现2次就会计算到进程树的总内存中,也就是说如果没有在3秒内调用exec就很有可能导致进程被杀,这种情况在高负载的集群中很有可能会出现。
知道了原理,通过搜索源码中创建进程相关内容定位到:Spark集群有个进程树内存占用指标统计被打开,统计执行时会创建pgrep进程来获取进程树,通过--conf spark.executor.processTreeMetrics.enabled=false参数关闭该功能后,没有再出现Container被杀的情况。