数据分析领域正在见证许多用例从批处理到流处理的演变。尽管批处理可以被作为流处理的一个特殊例子,处理永不结束的流式数据通常需要转换思维方式且通常有自己的术语(例如“窗口”和“最少一次/只有一次”处理)。这对于新接触流处理的人来说可能会相当疑惑。Flink是一个可用于生产的流处理器,具有易于使用但有表现力的API来构建高级流式分析程序。Flink的API在数据流窗口的定义十分灵活,使其从其他开源流处理器中脱颖而出。
在这篇文章中,我们将讨论流式处理窗口的概念,展示Flink内置窗口并解释其对自定义窗口语义的支持。
什么是窗口,窗口有什么用?
考虑这样一个例子:有一个交通传感器记录每15秒通过特定区域的车辆数量。结果流看起来是这样的:
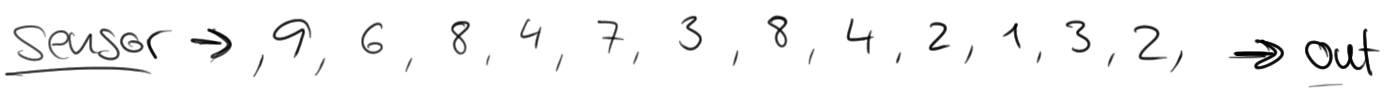
如果你单单想知道有多少量车通过了这一区域,可以简单的把这些数字加起来。然而,传感器流的天性是持续不断的产生数据。这种流不会结束并且不可能计算出一个最终的和。取而代之的是计算滚动的和,换句话说,对每一个输入事件都输出一个更新后的和。这将会产生一个新的部分和的流。
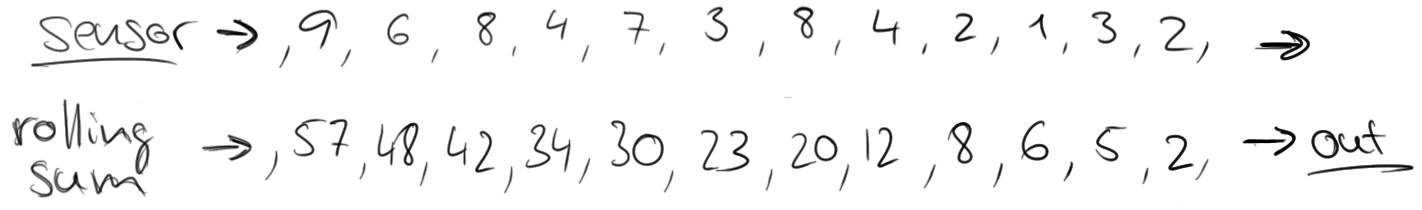
然而,这可能不是我么想要的,因为它总在更新,更重要的是有些信息,例如随时间的变化会丢失。于是,我们想修改问题,计算每分钟通过该区域的车数量。这要求我们将流中的元素分组到有界集合中,每个集合对于60秒。这个操作被称为滚动窗口操作。
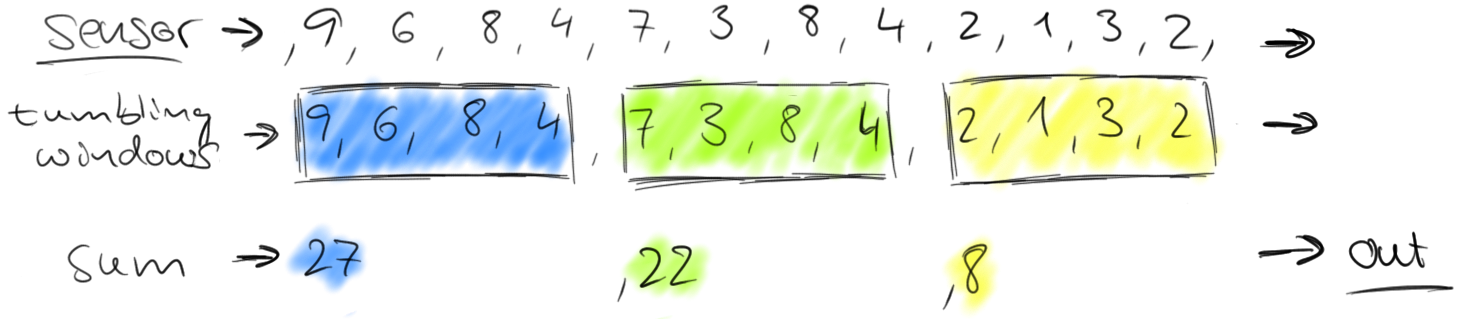
滚动窗口将流分散成不重叠的窗口。对于某些应用窗口不分离是十分重要的,因为需要平滑的聚合。例如,我们可以每30秒计算过去一分钟通过的车数量。这种窗口被成为滑动窗口。
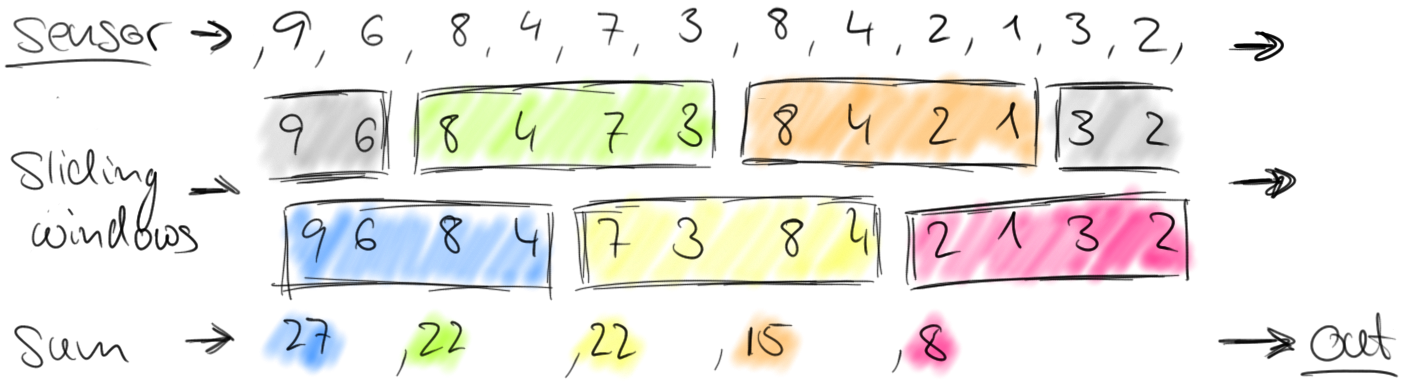
我们之前讨论过,在数据流中定义窗口是非并行操作。这是因为数据流中的每一个元素都必须被决定其被添加到哪一个窗口的同一个窗口算子处理。在整个流上开窗的操作在Flink称为全窗口。对于许多应用,一个数据流需要被费租到多个可以被应用窗口的逻辑流。思考一个关于多个传感器统计车流量到一条流的例子(不像上一个例子只有一个传感器),每一个传感器健康不同地点。通过对传感器的id进行分组,我们可以并行计算出多个地点窗口内的交通量统计。在Flink中,我们简称这种分区窗口为窗口,因为它们是分布式系统中很常见的情况。下图展示了滚动窗口从(传感器id,数量)的流中收集两个元素。
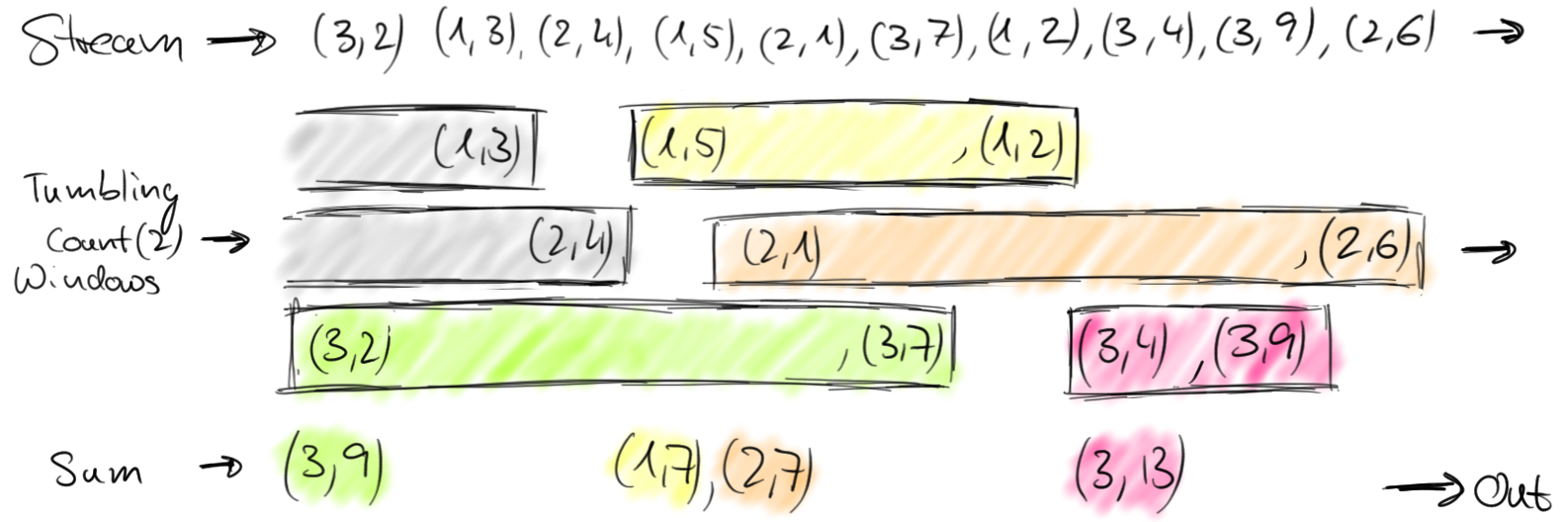
通常来说,窗口在无界流上定义了一组有限元素。这个分组可以基于时间(如同上述例子),元素的数量,时间和数量的组合,或者其他自定义逻辑来分配元素到窗口中。接下来在我们讨论窗口机制细节之前,我们先展示Flink的时间和数量窗口。
时间窗口
如同名字所示,时间窗口通过时间来对流上元素进行分组。例如,一个一分钟的滚动窗口收集一分钟内的元素,并在一分钟后对收集的元素调用指定方法。
定义滚动和滑动窗口在Flink是很容易的:
// Stream of (sensorId, carCnt)
val vehicleCnts: DataStream[(Int, Int)] = ...
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// key stream by sensorId
.keyBy(0)
// tumbling time window of 1 minute length
.timeWindow(Time.minutes(1))
// compute sum over carCnt
.sum(1)
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// sliding time window of 1 minute length and 30 secs trigger interval
.timeWindow(Time.minutes(1), Time.seconds(30))
.sum(1)还有一个方面我们尚未讨论,对于“收集一分钟元素”的精确定义最终归结到这个问题,“流处理器如何解释时间?”
Flink支持3种不同的时间概念,即处理时间,事件时间和摄取时间。
- 在处理时间,窗口是相对于构建和处理窗口的机器时钟时间定义的,换句话说,一分钟的处理时间窗口只收集一分钟元素。
- 在事件时间,窗口是相对于关联到记录上的时间戳来定义的。这在很多类型的事件是十分常见的,例如日志条目,传感器数据等等,时间戳通常代表这些事件发生的时间。事件时间相对于处理时间有几个优势。首先,它将程序语义与源的实际服务速度和系统处理性能解耦。因此你可以使用相同的程序按照最大速度处理历史数据,并持续输出数据。同时还可以避免因为因被压或者失败恢复延迟而导致的语义不正确。其次,事件时间窗口即使在事件乱序到达时也能计算正确结果,这在分布式数据源是很常见的。
- 摄入时间是处理时间和事件时间的混合产物。当记录到达时(到达source)根据时钟时间授予记录时间戳,然后基于该时间戳按照事件时间的语义继续处理。
计数窗口
Flink还支持计数窗口。一个100的滚动计数窗口会收集100条事件并在添加第100个元素时对窗口进行计算。
在Flink的DataStream API,滚动和滑动计数窗口可以按如下方式定义:
// Stream of (sensorId, carCnt)
val vehicleCnts: DataStream[(Int, Int)] = ...
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// key stream by sensorId
.keyBy(0)
// tumbling count window of 100 elements size
.countWindow(100)
// compute the carCnt sum
.sum(1)
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// sliding count window of 100 elements size and 10 elements trigger interval
.countWindow(100, 10)
.sum(1)Flink窗口机制剖析
Flink内置时间和计数窗口能够覆盖广泛的窗口通用用例。然而,肯定有一些应用需要无法被Flink内置窗口支持的自定义窗口逻辑。为了支持需要特定窗口语义的应用,DataStream API针对内部窗口机制暴露了接口。这些接口提供了细粒度的窗口构建和处理。
如下图描绘了Flink的窗口机制并介绍了相关组件。
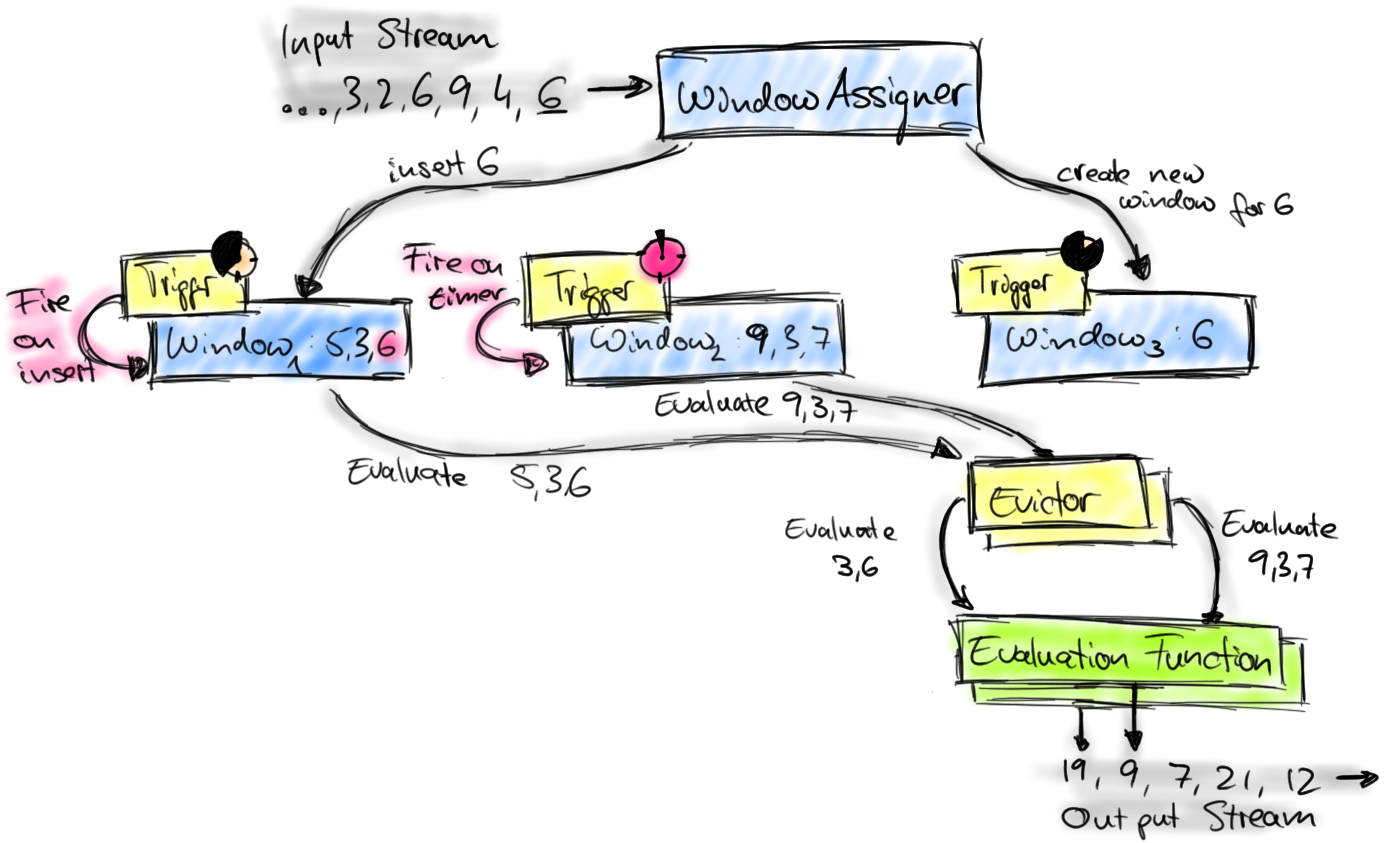
到达窗口算子的元素被交给WindowAssigner。WindowAssigner将元素分配给一个或多个窗口,可能会创建一个新的窗口。一个窗口只是一个list中包含元素元素的标识,同时还可能提供一些元数据,例如时间窗口中的开始时间和结束时间。注意元素可以被加入到多个窗口,这也就意味着多个窗口可以同时存在。
每一个窗口包含一个Trigger来决定窗口何时被计算和清空。Trigger在每次插入元素和之前注册timer超时时被调用。每次触发事件时,由trigger决定进行计算,清空,或者计算并清空窗口。只触发计算的trigger会使window保持原样,换句话说,所有窗口中的元素会在下次触发时再次被计算。一个窗口可以被多次计算直到被清空。注意窗口会一直占用内存直到被清空。
当trigger被触发,窗口中包含元素的list交给一个可选的Evictor。Evictor可以遍历整个list并决定是否从list头部剔除部分元素,换句话说,移除先进入窗口的部分元素。剩余的元素被交给一个evaluation方法。如果没有evictor被定义,Trigger将所有元素直接交给evaluation方法。
evaluation方法接收窗口中的元素并计算出一条或多条结果。DataStream API接受不同类型的evaluation方法,包括预定义的诸如sum(),min(),max()这类聚合方法,也支持ReduceFunction,FoldFunction或者WindowFunction。WindowFunction是最为通用的evaluation方法,能够接受window对象(即窗口的元数据),window元素的list,窗口的key(如果是keyed窗口)作为参数。
这就是组成Flink窗口机制的组件。我们现在展示如何通过DataStream API一步步实现自定义窗口逻辑。我们从一个DataStream[IN]开始,并使用key selector方法来获取一个KeyedStream[IN, KEY]
val input: DataStream[IN] = ...
// created a keyed stream using a key selector function
val keyed: KeyedStream[IN, KEY] = input
.keyBy(myKeySel: (IN) => KEY)我们应用WindowAssigner[IN, WINDOW]来创建WINDOW类型的窗口,最终得到一个WindowedStream[IN, KEY, WINDOW]。此外,WindowAssigner还包含一个默认的Trigger实现。
// create windowed stream using a WindowAssigner
var windowed: WindowedStream[IN, KEY, WINDOW] = keyed
.window(myAssigner: WindowAssigner[IN, WINDOW])我们可以显式指定一个Trigger来覆盖WindowAssigner的默认Trigger。注意,指定一个trigger不是新增一个额外的trigger条件,而是替换现有的trigger。
// override the default trigger of the WindowAssigner
windowed = windowed
.trigger(myTrigger: Trigger[IN, WINDOW])我们可能想要指定一个可选的Evictor
// specify an optional evictor
windowed = windowed
.evictor(myEvictor: Evictor[IN, WINDOW])最后,我们应用一个返回类型为Out的WindowFunction来获得获取一个DataStream[OUT]
// apply window function to windowed stream
val output: DataStream[OUT] = windowed
.apply(myWinFunc: WindowFunction[IN, OUT, KEY, WINDOW])通过Flink内置的窗口机制和其通过DataStream API暴露的接口可以实现非常自定义的诸如session窗口或者到达某个阈值就提交结果的窗口逻辑。
结论
支持持续数据流的多种类型窗口是现代流处理器必备的功能。Flink是一个具有非常强大功能集的流处理器,包含了一个非常灵活的机制来创建和计算持续数据流上的窗口。Flink提供了预定义窗口算子来满足通用常见,同时也提供了允许自定义窗口逻辑的工具集。随着用户需求的理解,Flink社区会添加更多预定义窗口算子。
https://flink.apache.org/news/2015/12/04/Introducing-windows.html